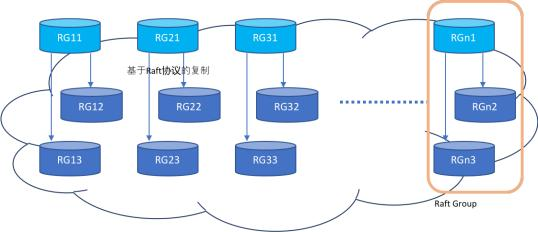
数据存储流向图 数据存储环节的关键要素
在当今数据驱动的时代,理解数据从产生到最终被利用的完整生命周期至关重要。数据存储流向图(Data Storage Flow Diagram)是描绘这一生命周期中数据存储环节的关键工具。它并非简单地展示数据存放在哪里,而是系统性地呈现数据在不同存储介质、系统或架构之间的流动、转换与持久化过程,是系统架构设计、数据治理和合规审计的核心蓝图。
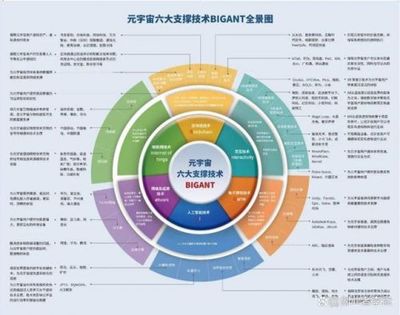
一、 数据存储流向图的核心构成
一个典型的数据存储流向图通常包含以下几个核心要素:
1. 数据源(Data Sources):
这是数据旅程的起点,包括各种业务系统(如ERP、CRM)、物联网设备、日志文件、外部API、用户生成内容等。流向图需明确标识不同数据源的格式和产生频率。
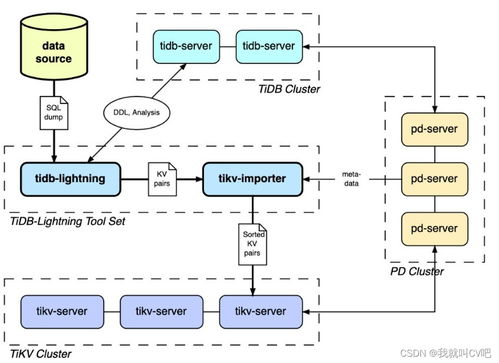
2. 采集与接入层(Ingestion Layer):
负责从数据源捕获数据,常见组件包括ETL(提取、转换、加载)工具、实时数据流平台(如Apache Kafka)、数据管道等。此层决定了数据进入存储系统的初始方式和节奏(批量或实时)。
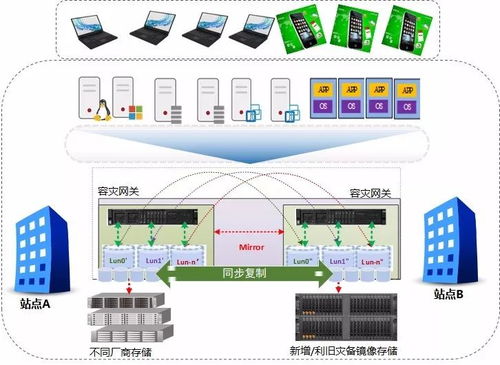
3. 存储介质与系统(Storage Media & Systems):
这是流向图的核心,展示了数据被具体存放的位置及其层次关系。通常包括:
- 热存储:用于处理高频访问的在线事务,如关系型数据库(MySQL, PostgreSQL)、NoSQL数据库(MongoDB, Redis)。
- 温存储:用于分析和查询,如数据仓库(Snowflake, BigQuery)、分布式数据库(ClickHouse)。
- 冷存储/归档存储:用于合规性归档或极少访问的历史数据,如对象存储(Amazon S3, 阿里云OSS)、磁带库。
- 缓存层:如Redis或Memcached,用于加速热点数据访问。
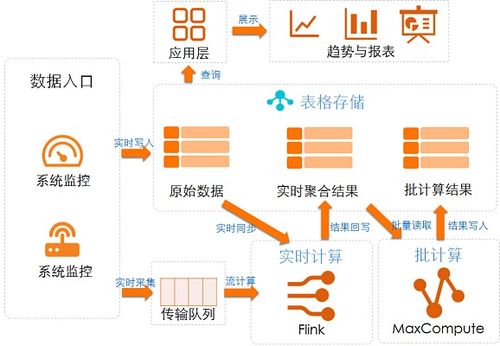
4. 处理与计算层(Processing & Computation Layer):
数据存储后,往往需要被加工。此层包括批处理引擎(如Apache Spark)、流处理引擎(如Apache Flink)以及在其上运行的数据处理任务,它们会读取原始存储中的数据,进行计算、聚合后,将结果写回另一类存储(如从数据湖写入数据仓库)。
5. 服务与消费层(Serving & Consumption Layer):
数据价值的最终体现。包括BI报表工具、数据API、机器学习模型服务、前端应用程序等。它们从经过处理的存储层中查询和获取数据,服务于最终用户或下游系统。
6. 流向与元数据(Flow Directions & Metadata):
箭头是流向图的“语言”,清晰标示数据移动的方向、顺序和触发条件(如定时任务、事件驱动)。应补充关键元数据,如数据格式、数据量、延迟要求(SLA)、保留策略和安全等级。
二、 绘制数据存储流向图的价值
- 架构清晰化与沟通:为技术、产品、运维团队提供统一的“地图”,便于理解系统全貌,减少沟通成本。
- 瓶颈识别与优化:直观暴露数据流转过程中的性能瓶颈、单点故障或冗余存储,为系统优化提供依据。
- 成本管控:关联不同存储方案的成本,有助于合理规划数据分层,将合适的数据放在性价比最优的存储上。
- 数据治理与合规:明确数据的“住址”和“行踪”,是实施数据质量管理、血缘追踪、访问控制和满足GDPR等数据法规要求的基础。
- 影响分析:当某个存储系统需要变更或下线时,可快速评估其对上下游系统的影响范围。
三、 实践建议
- 分层与视角:可以绘制不同粒度的流向图,如全局系统级、单个应用级或专注于某一领域(如日志数据流)。
- 保持更新:系统架构和数据流水线是动态演进的,流向图必须与实际情况同步更新,最好能纳入CI/CD流程或架构文档的常规维护。
- 工具辅助:可使用Draw.io、Lucidchart、Miro等绘图工具,或利用DataHub、Amundsen等数据目录工具自动生成部分血缘关系。
结论
数据存储流向图是驾驭复杂数据生态系统的导航仪。它超越了静态的拓扑图,动态地揭示了数据在存储层面的生命轨迹。精心设计和维护一份准确、清晰的流向图,是保障数据资产被高效、安全、经济地管理和利用的基石,对于任何致力于数据驱动决策的组织而言,都是一项不可或缺的基础工作。
如若转载,请注明出处:http://www.wzswzz.com/product/9.html
更新时间:2026-06-19 17:41:13